This article was first published in Towards Data Science.
Introduction
Fuzzy-Logic theory has introduced a framework whereby human knowledge can be formalized and used by machines in a wide variety of applications, ranging from cameras to trains. The basic ideas that we discussed in the earlier posts were concerned with only this aspect with regards to the use of Fuzzy Logic-based systems; that is the application of human experience into machine-driven applications. While there are numerous instances where such techniques are relevant; there are also applications where it is challenging for a human user to articulate the knowledge that they hold. Such applications include driving a car or recognizing images. Machine learning techniques provide an excellent platform in such circumstances, where sets of inputs and corresponding outputs are available, building a model that provides the transformation from the input data to the outputs using the available data.
In this post, we will discuss an algorithm that constructs a Fuzzy System from data that was presented by Professor Li-Xin Wang and Professor Jerry Mendel. One exciting aspect of this and similar techniques is the ability to obtain knowledge that can be easily understood by humans in the form of fuzzy sets and rules from data.
Procedure
The objective of this exercise is, as we have explained in the introduction, given a set of input/output combinations, we will generate a ruleset that determines the mapping between the inputs and outputs. In this discussion, we will consider a two-input, single-output system. Extending this procedure for more complex systems should be a straightforward task to the reader.
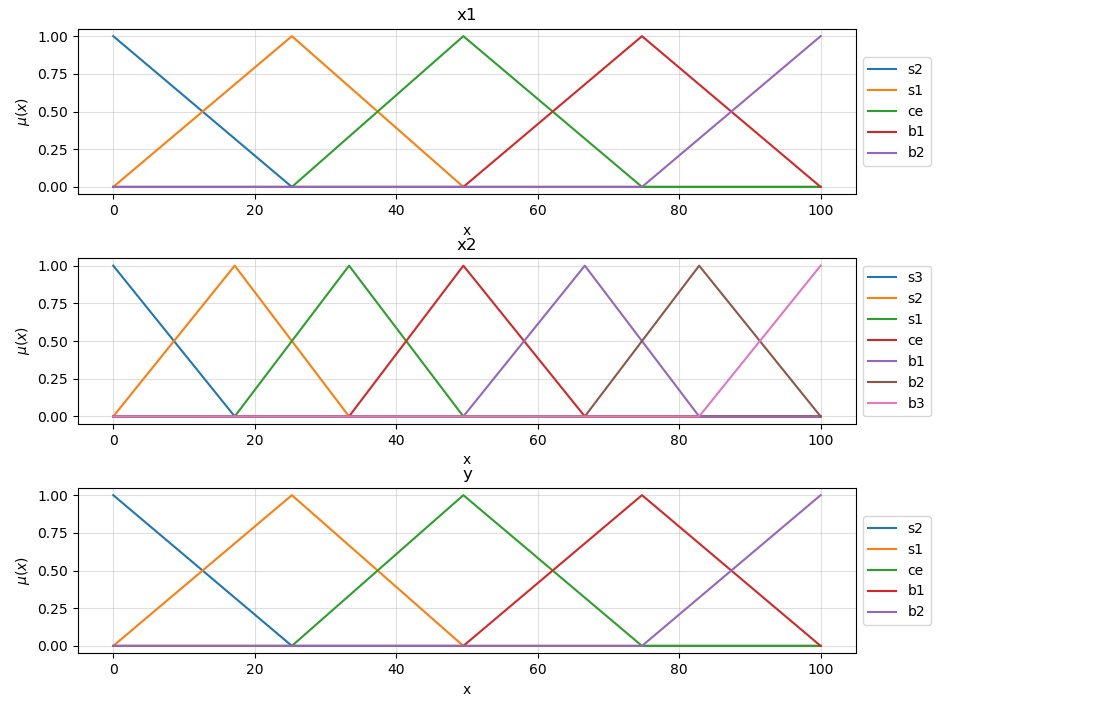
Step 1 — Divide the input and output spaces into fuzzy regions.
We start by assigning some fuzzy sets to each input and output space. Wang and Mendel specified an odd number of evenly spaced fuzzy regions, determined by 2N+1 where N is an integer. As we will see later on, the value of N affects the performance of our models and can result in under/overfitting at times. N is, therefore, one of the hyperparameters that we will use to tweak this system’s performance.
Step 2 — Generate Fuzzy Rules from data.
We can use our input and output spaces, together with the fuzzy regions that we have just defined, and the dataset for the application to generate fuzzy rules in the form of:
If {antecedent clauses} then {consequent clauses}
We start by determining the degree of membership of each sample in the dataset to the different fuzzy regions in that space. If, as an example, we consider a sample depicted below:
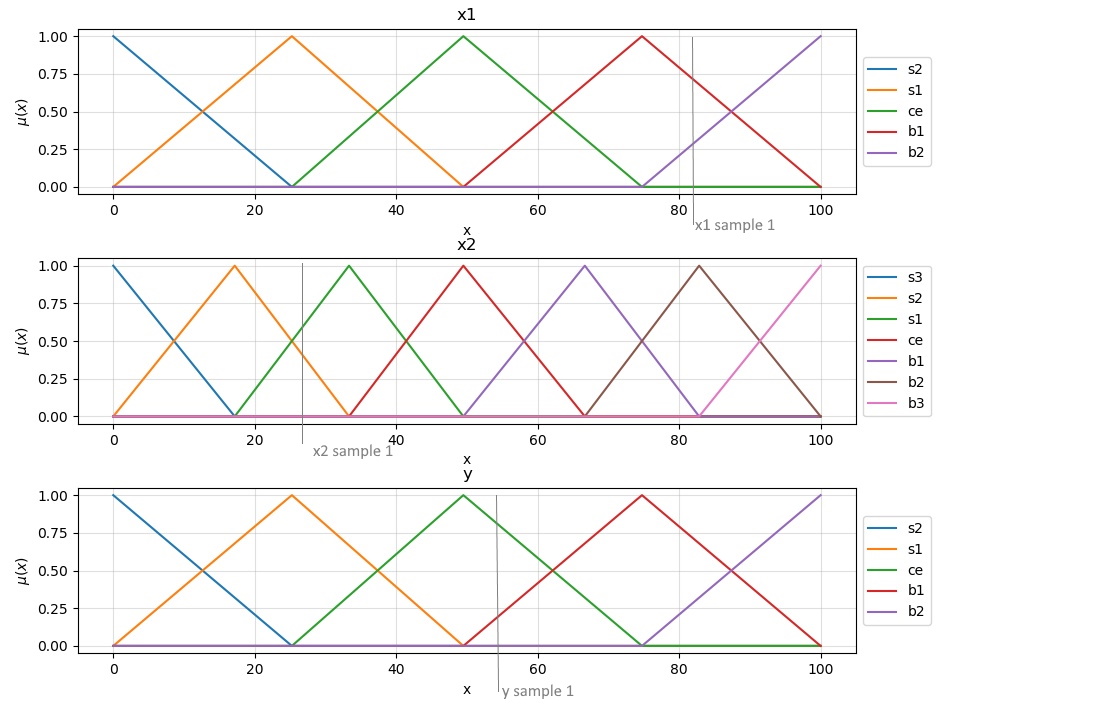
we obtain the following degrees of membership values.

We then assign the region having the maximum degree of membership of to the spaces, which is indicated by the highlighted elements in the above table so that it is possible to obtain a rule:
sample 1 => If x1 is b1 and x2 is s1 then y is ce => Rule 1
The next illustration shows a second example, together with the degree of membership results that it generates.
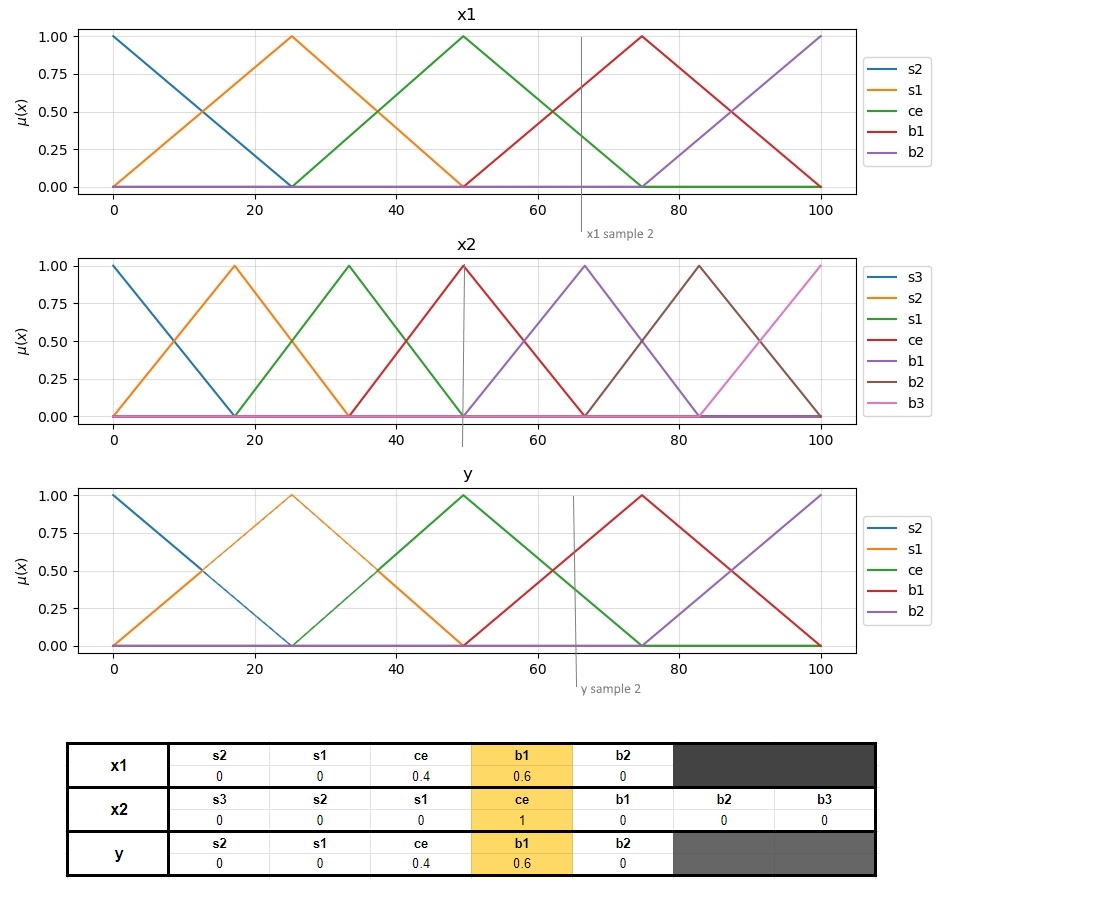
This sample will, therefore, produce the following rule:
sample 2=> If x1 is b1 and x2 is ce then y is b1 => Rule 2
Step 3 — Assign a degree to each rule.
Step 2 is very straightforward to implement, yet it suffers from one problem; it will generate conflicting rules, that is, rules that have the same antecedent clauses but different consequent clauses. Wang and Medel solved this issue by assigning a degree to each rule, using a product strategy such that the degree is the product of all the degree-of-membership values from both antecedent and consequent spaces forming the rule. We retain the rule having the most significant degree, while we discard the rules having the same antecedent but a having a smaller degree.
If we refer to the previous example, the degree of Rule 1 will equate to:
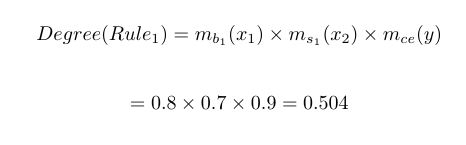
and for Rule 2 we obtain:
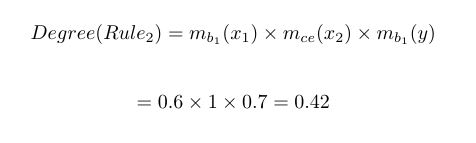
We notice that this procedure reduces the number of rules radically in practice.
It is also possible to fuse human knowledge to the knowledge obtained from data by introducing a human element to the rule degree, that has high applicability in practice, as human supervision can assess the reliability of data, and hence the rules generated from it directly. In the cases where human intervention is not desirable, this factor is set to 1 for all rules. Rule 1 can be hence defined as follows;
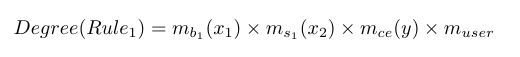
Step 4 — Create a Combined Fuzzy Rule Base
The notion of the Combined Fuzzy Rule Base was examined in a previous post. It is a matrix that holds the fuzzy rule-base information for a system. A Combined Fuzzy Rule Base can contain the rules that are generated numerically using the procedure described above, but also rules that are obtained from human experience.
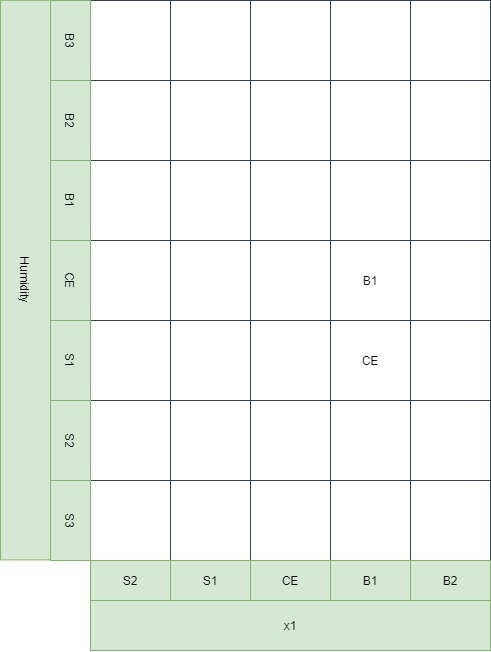
Step 5 — Determine a mapping based on the Combined Fuzzy Rule Base.
The final step in this procedure explains the defuzzification strategy used to determine the value of y, given (x1, x2). Wang and Mendel suggest a different approach to the max-min computation used by Mamdani. We have to consider that, in practical applications, the number of input spaces will be significant when compared to the typical control application where Fuzzy Logic is typically used. Besides, this procedure will generate a large number of rules, and therefore it would be impractical to compute an output using the ‘normal’ approach. For a given input combination (x1, x2), we combine the antecedents of a given rule to determine the degree of output control corresponding to (x1, x2) using the product operator. If
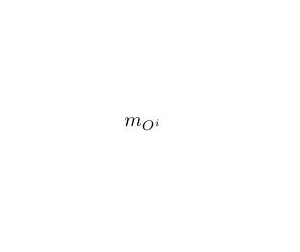
is the degree of output control for the ith Rule,
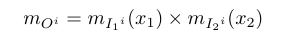
Therefore for Rule 1
If x1 is b1 and x2 is s1 then y is ce
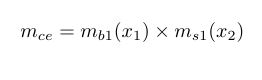
We now define the centre of a fuzzy region as the point that has the smallest absolute value among all points at which the membership function for this region is equal to 1 as illustrated below;
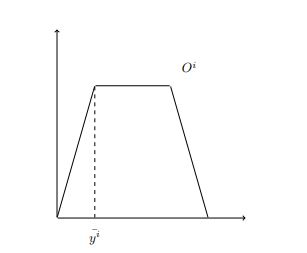
The value of y for a given (x1, x2) combination is thus
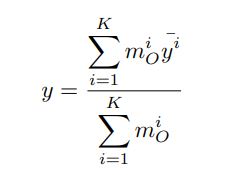
where K is the number of rules.
Testing
A (very dirty) implementation of the above algorithm was developed in Python to test it with real datasets. The code and data used are available in Github. Some considerations on this system include.
-
The fuzzy system is generated from the test data directly.
-
The sets were created using the recommendation in the original paper, that is evenly spaced. It is, however, interesting to see the effects of changing this method. One idea is to have sets created around the dataset mean with a spread relatable to the standard deviation — this might be investigated in a future post.
-
The system created does not cater for categorical data implicitly, and this is a future improvement that can affect the performance of the system considerably in real-life scenarios.
Testing metrics
We will use the coefficient of determination (R-Squared) to assess the performance of this system and to tune the hyperparameter that was identified, the number of fuzzy sets generated.
To explain R-Squared, we must first define the sum of squares total and the sum of squares residual.
The sum of squares total is the sum of the squared difference between the dependent variable (y) and the mean of the observed dependent variable.
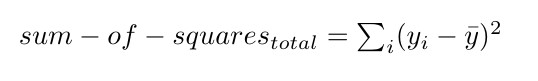
The sum of squares residual is the sum of the squared difference between the actual and estimated value of the dependent variable.
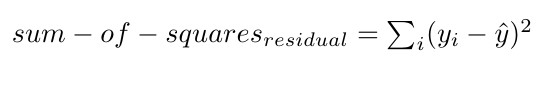
R-Squared can be then calculated as
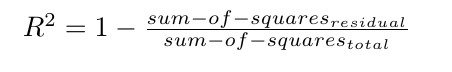
we notice that R-Squared will have a value between 0 and 1, the larger, the better. If R-Squared =1, then there is no error and the estimated values will be equal to the actual values.
Case Study 1 — Noisy Sensor
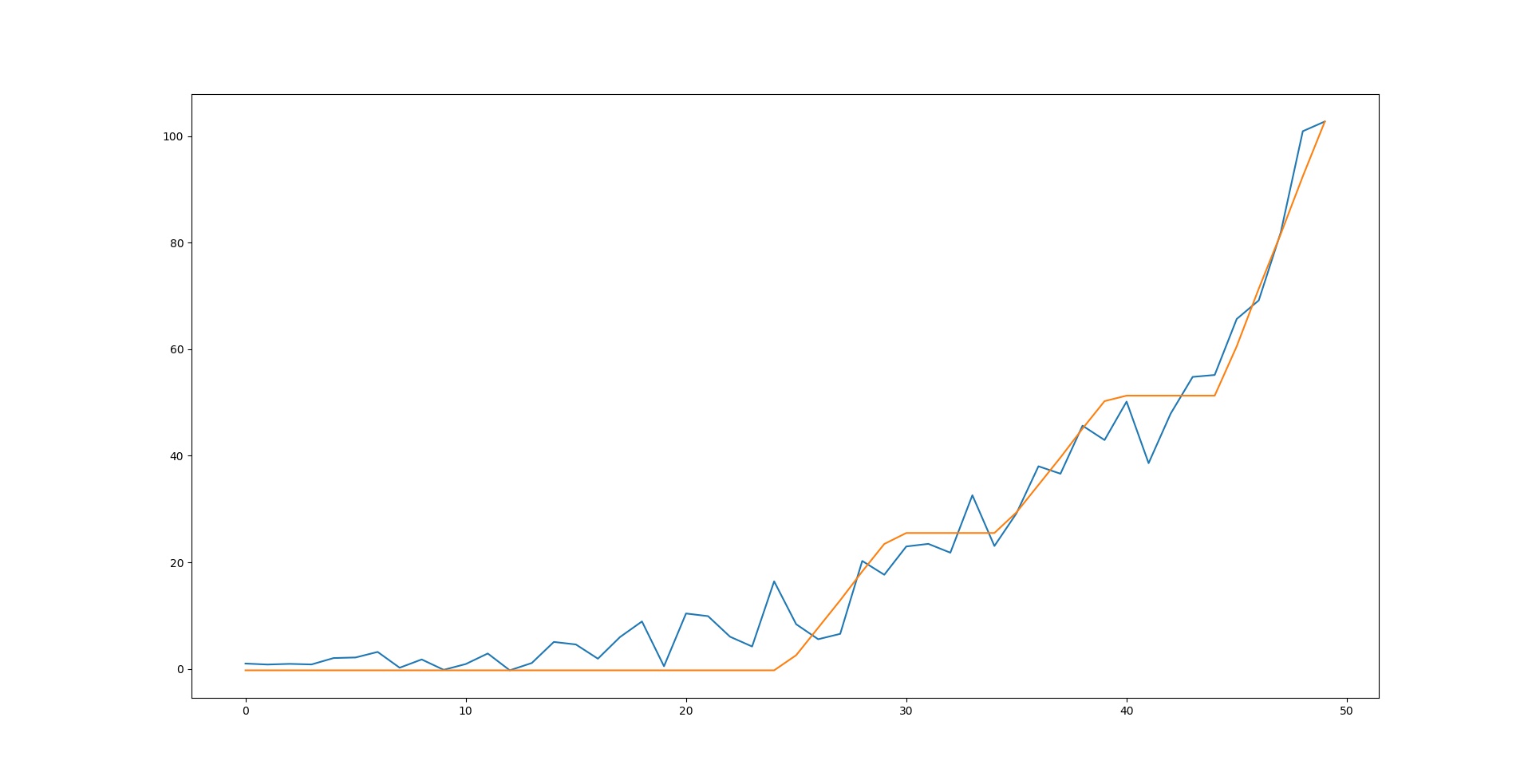
We begin testing the procedure with a straightforward application; a single-input, single-output system that represents a hypothetical sensor that has an exponential response. To complicate things a little, we have added some noise to the sensor data as can be shown in the image below:
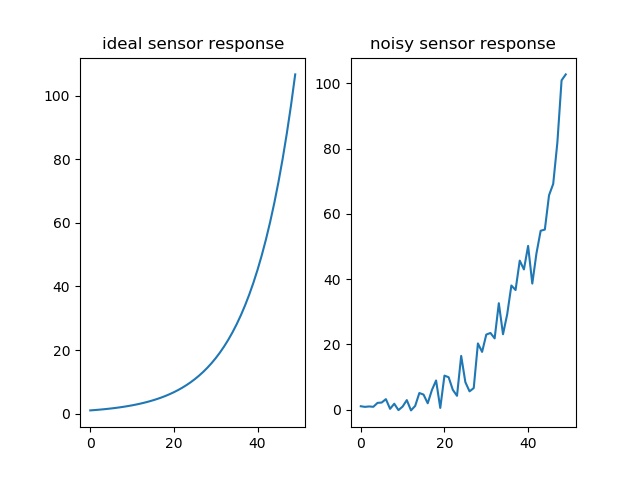
We start by examining the various outcomes for the different values of N for x and y. The following illustrations formed the results that were obtained during the search for the best values.
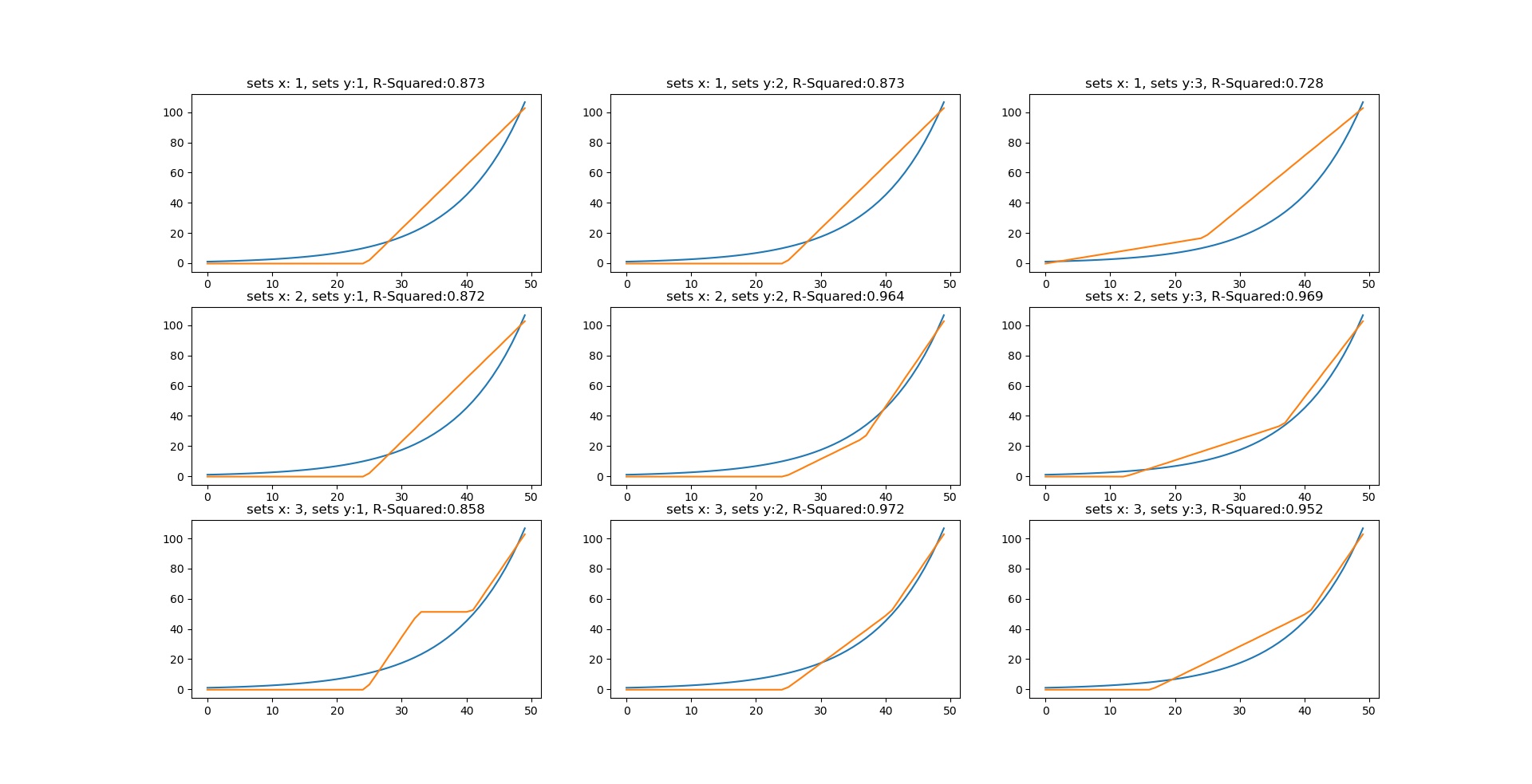
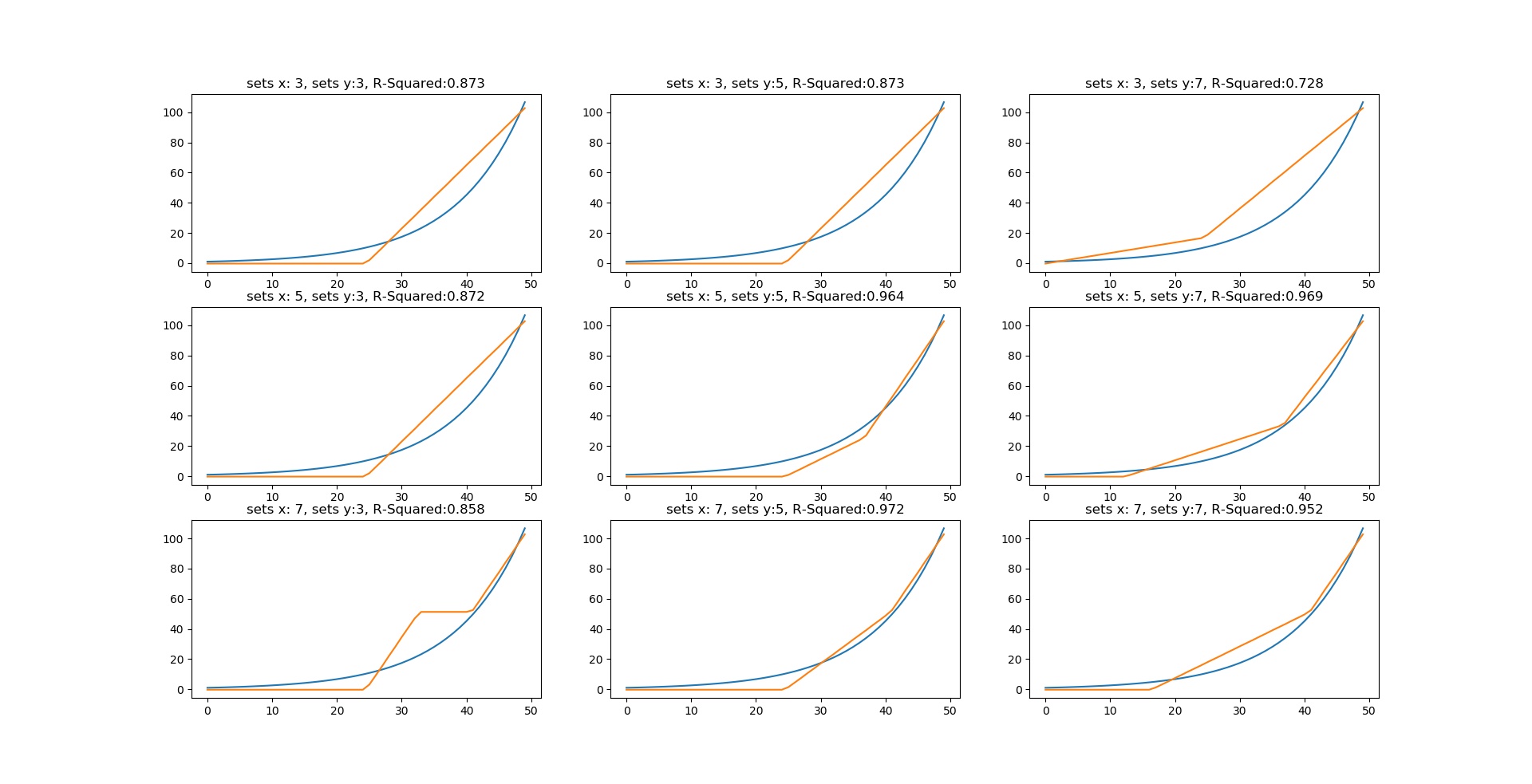
The best response is obtained when setting the value of N_x to 4 and N_y to 3, attaining an R-squared value of 0.985. The rules generated by the system are of particular interest as they can explain how the system is working in a way that can be easily understood;
If x is s4 then Y is s3
If x is s3 then Y is s3
If x is s2 then Y is s3
If x is s1 then Y is s3
If x is ce then Y is s2
If x is b1 then Y is s2
If x is b2 then Y is s1
If x is b3 then Y is ce
If x is b4 then Y is b3
We notice that the characteristics of a system displaying exponential properties are clearly explained. The output value remains the smallest possible for all small values of the input, increasing very rapidly as the values of the input increase further.
The system is also susceptible to overfitting as can be noticed for the values like N_x=5 and N_y=2.
Case Study 2 — Temperature
For a second test, we have used the Weather in Szeged 2006–2016 available at Kaggle. The dataset has over 96,000 training examples that consist of 12 features.
Formatted Date object
Summary object
Precip Type object
Temperature (C) float64
Apparent Temperature (C) float64
Humidity float64
Wind Speed (km/h) float64
Wind Bearing (degrees) float64
Visibility (km) float64
Loud Cover float64
Pressure (millibars) float64
Daily Summary object
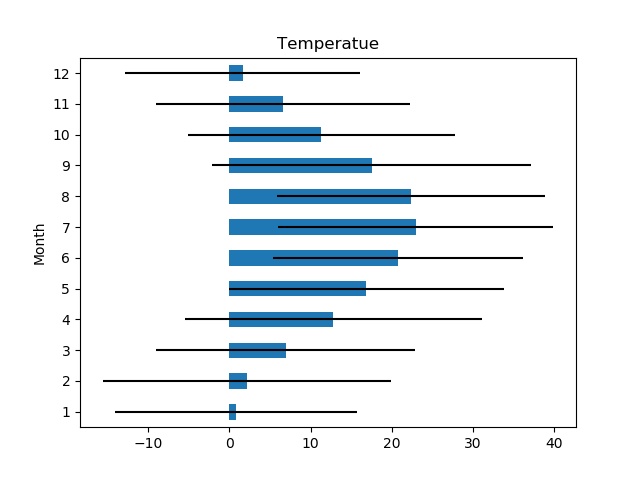
For this exercise, we will be discarding most of these features and assess if we can predict the temperature given the month and humidity. Upon examining the data, we notice that the average temperature varied between 1 and 23 degrees Celcius with a variability of about 20 degrees per month.
The average humidity varies between 0.63 and 0.85, but we also notice that it is always possible to reach 100%, irrelevant of the month.
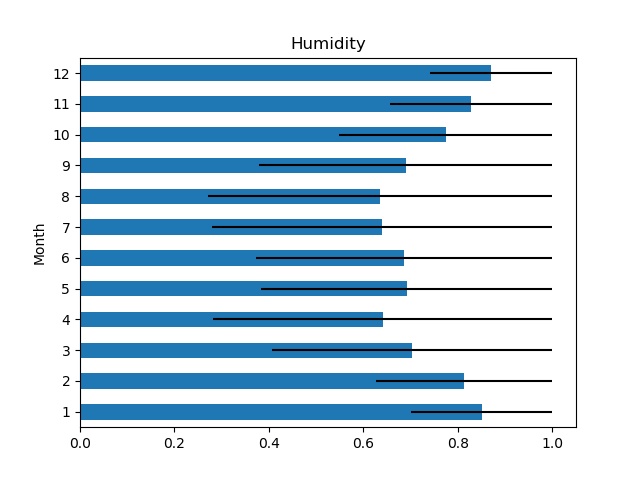
The best Fuzzy system that was tested consisted of 3 fuzzy spaces (N=1) for the input variables and nine fuzzy spaces (N=4) for the temperature. The system generated the nine rules depicted in the Fuzzy Distribution Map below and attained an R-Squared value of 0.75, using a test sample of 20%.
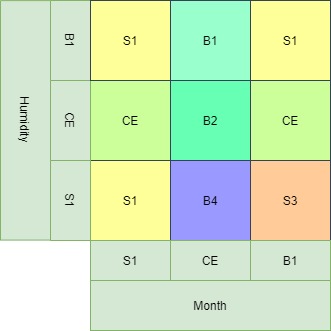
Conclusion
The system described above produces human-readable rules from data that can help us gain insights on complex systems. Below are several observations and ideas for future work:
- The system needs a considerable dataset that needs to cover all possible rules that can be generated. Therefore larger datasets are required as the number of features increase, as the number of rules required will grow exponentially.
- It might be possible to generate missing rules by examining the neighbouring ones. If an absent rule can be illustrated in a Combined Fuzzy Rule Base surrounded by the same output space, probably, the rule would then belong to the same space. This idea will be tested in the future.
- The distribution of the fuzzy spaces affects the performance of the system, although preprocessing like standardization and normalization help to limit the effect of data distribution on the system.
- The effect of handcrafted rules has to be investigated. It is interesting to verify if human experience can indeed augment the performance of a machine-generated system.
- It is also interesting to examine the data responsible for a rule and use the information to determine why a test sample yields a significant error.