Automated machine learning (AutoML) automates the creation of machine learning models. Typically, the process of creating a model can be long and tedious. AutoML makes it possible for people who do not have coding experience to develop and use ML models.
In a typical machine learning application, we start with raw data for Training. The data might have missing fields, contain outliers, and require cleaning work. The following steps might be required:
- Data pre-processing and feature engineering are often required to clean the data.
- Feature engineering, extraction, and transformation are often required to prepare the data for modelling.
- Algorithm selection
- Hyperparameter optimization
Each of these steps may be challenging, and tedious resulting in significant hurdles to using machine learning.
AutoML makes Training, running and deployment a no-code experience. It will go through a combination of algorithms and hyperparameters and searches until it finds the best model for the data, according to metrics defined by the user.
In this post, we will go through creating a model using AutoML.
The data
For this example, we will use the UCI Concrete dataset. This dataset contains data on the compressive strength of concrete given the mixture and curing time as features. The dataset is available from UCI Machine Learning Repository.
A dataset pointing to this data has been created in a previous post, used in this example.
Starting AutoML
AutoMl is started by selecting the AutoMl tab in the AzureML workspace and then beginning an AutoML job. We notice that the job consists of three steps:
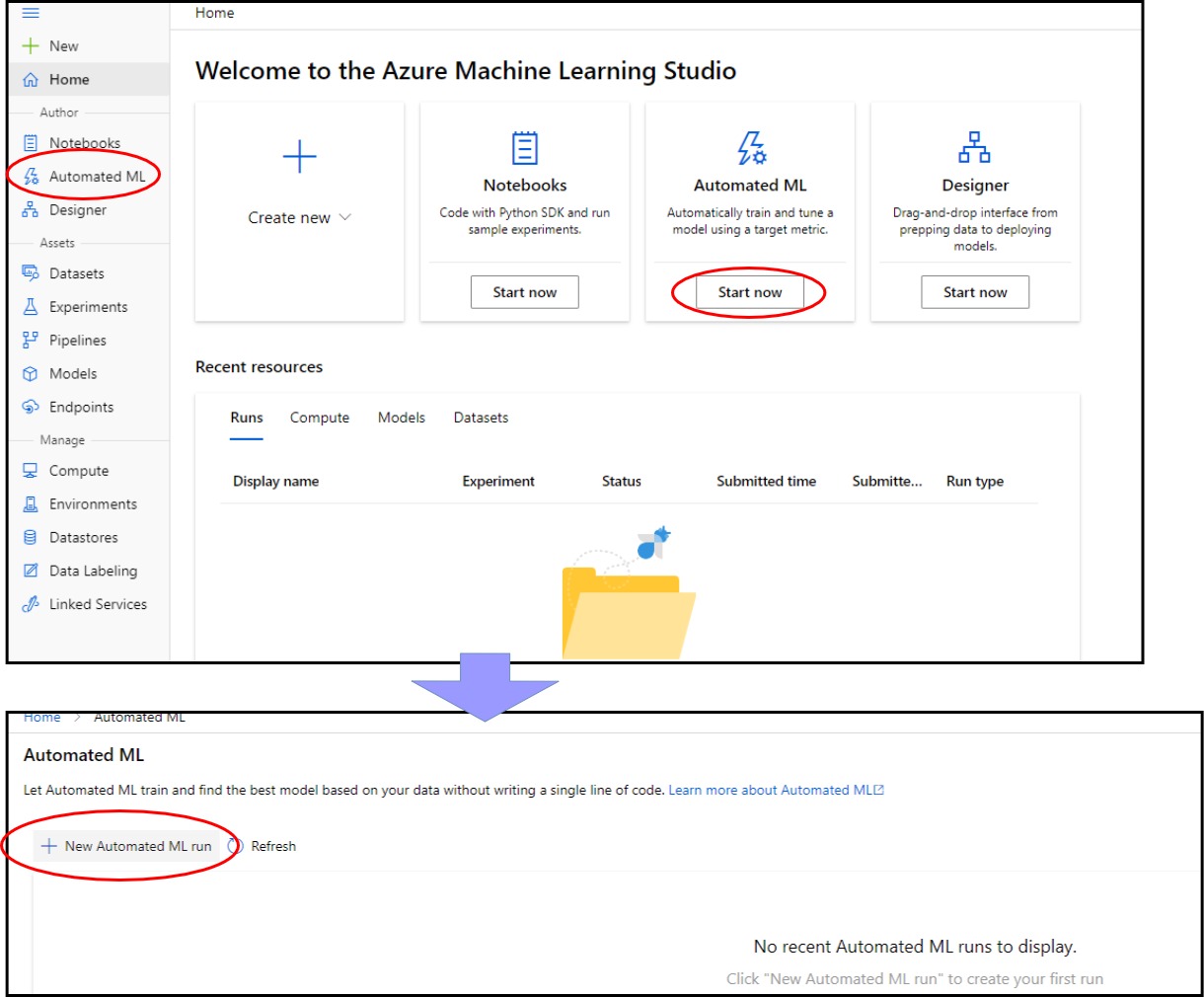
- Selecting the dataset
- Configuring the run
- Task and settings selection
- Validation and testing
Configuring the run
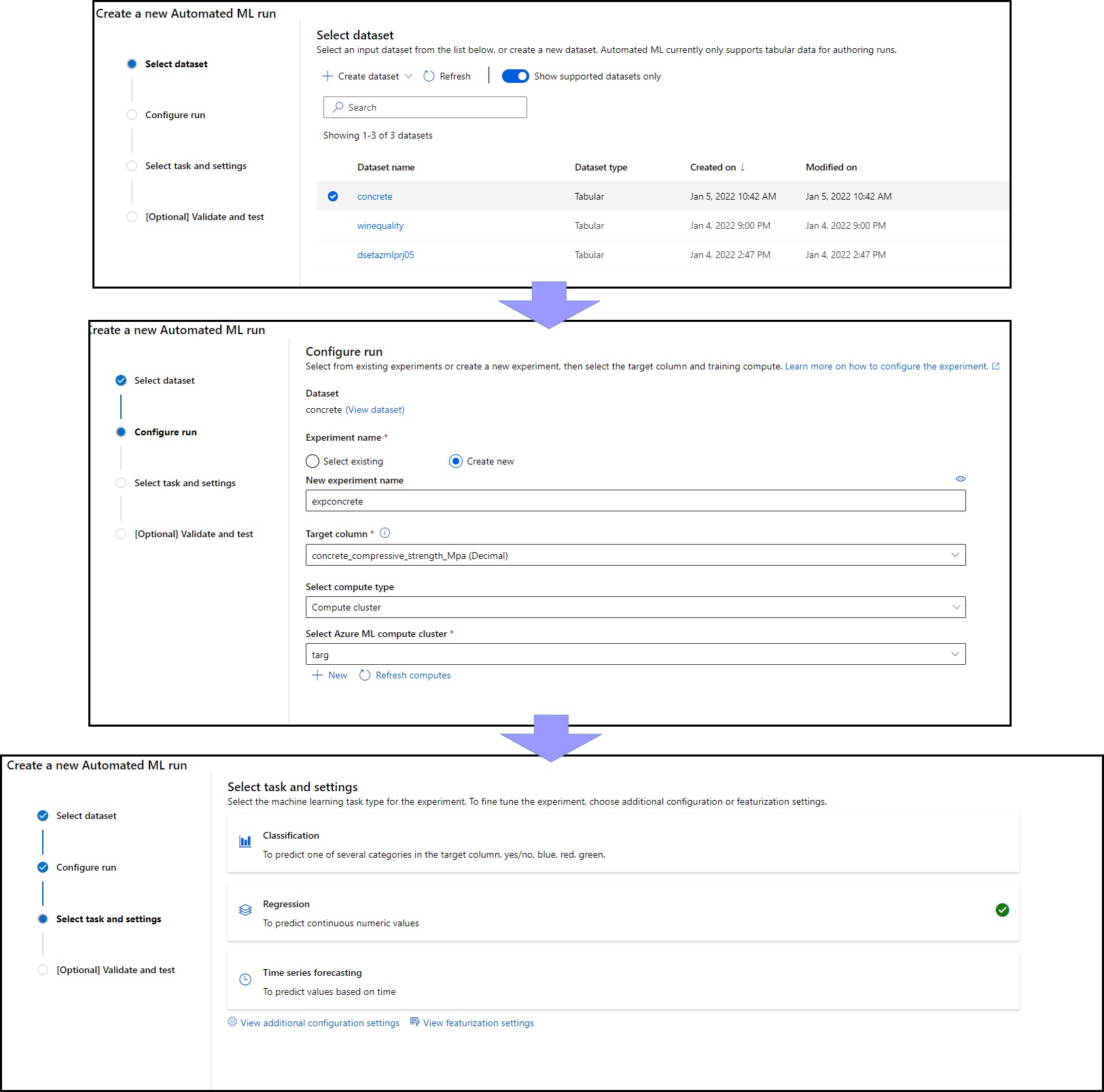
The first step is to select the dataset. This is very easy, as we have already created the dataset, so choosing it will suffice. It is also possible to create a new dataset at this stage.
The next step is to configure the run. There are several options available;
- Experiment name. We can use an already existing experiment or create a new one.
- Target Column, the column of the label we are trying to predict.
- Compute Type. The compute upon which AutoML will run. It is also possible to create a new compute at this stage.
The next step is to select the ML task for this experiment. We notice that AutoML tries to reason if the task is classification, regression or time series from the dataset, but it is possible to select a task manually. In our case, we notice that Regression is the most suitable task for this dataset as the label is numeric.
Additional Run Configuration
It is possible to further configure the run by
- Specifying additional settings
- Confirm featurization settings
In the Additional Settings section, we can specify
- the metric used for evaluation. In this case, we select the Normalized root mean squared error (NRMSE).
- the algorithm to use(actually, we select the algorithms that we do not want to use). Notice that we kept just two algorithms, Random Forest and Fast Linear Regression in this case.
- the maximum time to run each algorithm
- the threshold so that we can consider the algorithm as having converged to an acceptable metric value.
- Concurrency is the number of parallel algorithms that will be run, depending on the nodes available on the selected compute.

Featurization settings allow us to confirm the data types of the features. We can also select an inpute method for the missing data in each feature. In this case, the data does not have any missing values.
Validation Type and Starting the Run
Finally, the last step is to select the validation type. We select the validation type as train validation, which will split the data into a training and testing set. We chose a 20% testing set. We also noticed that it is possible to provide an external test set.
The AutoMl run is initialized and started. We noticed settings that we had specified, like the dataset and the compute, together with the status of the run.
Results
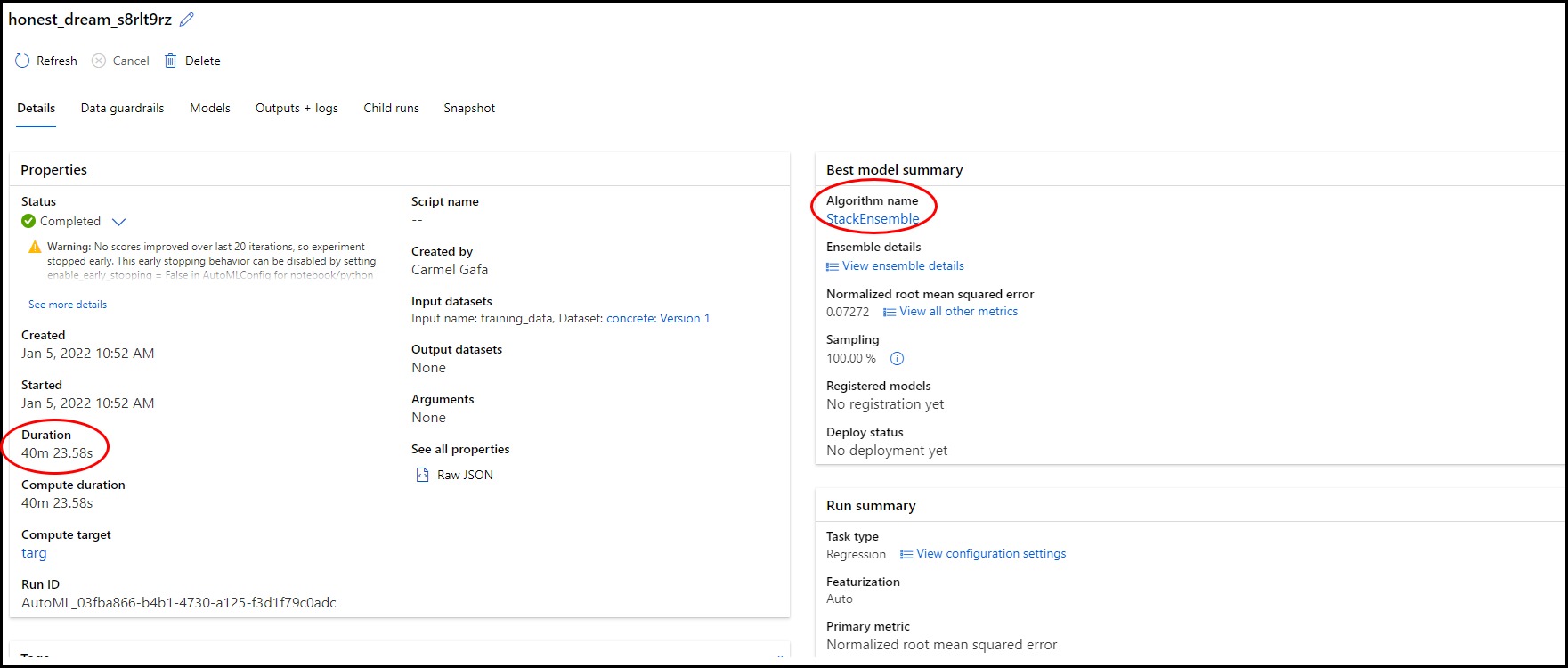
Upon completion of the run, we can see the results. We notice the following:
The run duration was about 40 minutes, which is in line with the preset time of 30 minutes per algorithm. We also noticed that one of the algorithms was stopped early as it converged.
The best model section gives us the following information about the selected model:
- The best algorithm was StackEnsembleRegressor
- the NRMSE of the best algorithm was 0.07, which is greater than the 5% that we specified. It looks like we were too ambitious.
Other sections give us information about the run.
Data Guardrails tells us the featurization steps performed during the run. No actions were performed on our dataset.
Models shows us the models created during the run and their scores, ascending on the primary metric as it was NRMSE.
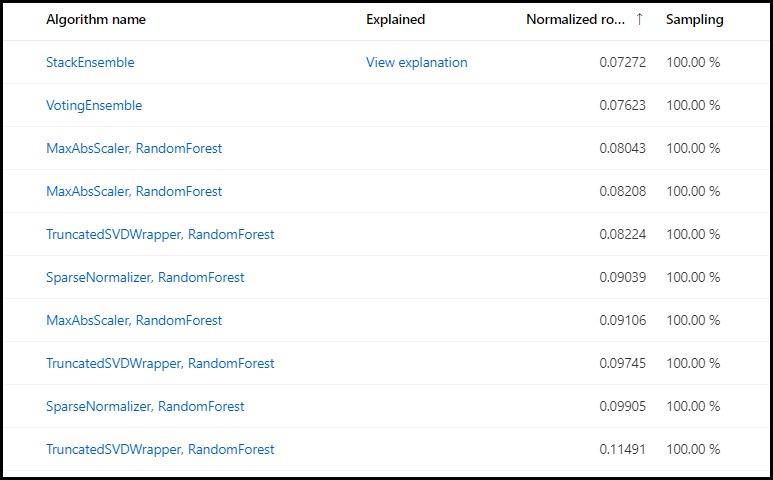
It is also possible to get more details on the selected model by selecting to view the explanation.
Model Explanation
Model explanation displays the top n features that affect the model. In our case, we notice that the curing time and cement are the top two features that affect the strength of concrete.
Deployment
We also notice that it is possible to deploy the model as an API that we can call. Azure allows us to deploy the model as an ACI or a Kubernetes service. A RESTful URL is given to consume the model.