Logistic regression is a machine learning algorithm that is commonly used for binary classification tasks.
Given a feature vector $X \in \mathbb{R}^{n_x}$, the goal of logistic regression is to predict the probability $\hat{y}$ that a binary output variable $y$ takes the value 1, given $X$, that is $\hat{y} = P(y=1|X)$, $0\le y\le1$. For example, in the case of image classification, logistic regression can be used to predict the probability that an image contains a cat.
 |
||
|---|---|---|
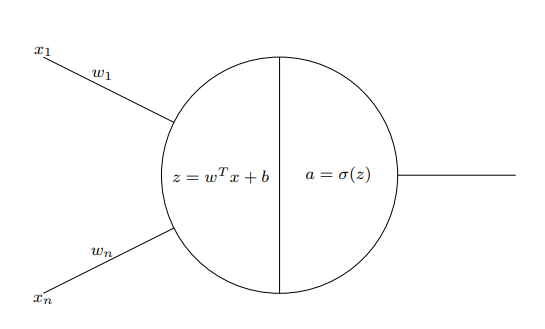
The logistic regression model consists of three main components:
- Parameters: A weight vector $\omega \in \mathbb{R}^{n_x}$ and a bias term $b \in \mathbb{R}$.
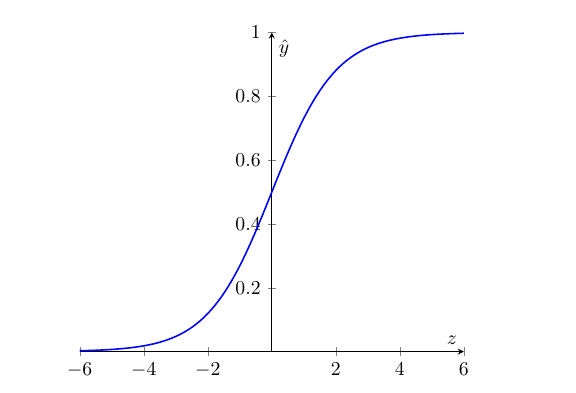
- Sigmoid function: A function $\sigma(z) = \frac{1}{1 + e^{-z}}$, which maps any real number $z$ to the range $(0,1)$. This function is used to ensure that the predicted probability $\hat{y}$ is always between 0 and 1.
- Output: The predicted probability $\hat{y}$ is computed as $\hat{y} = \sigma(\omega^{T}X + b)$.
The weight vector $\omega$ and the bias term $b$ are learned from a labelled training set by minimizing a suitable loss function using techniques such as gradient descent or its variants. Once trained, the logistic regression model can be used to predict the probability of the binary output variable for new input examples.
 |
||
|---|---|---|
The feedforward process for logistic regression can be described as follows:
- Compute $z$ as the dot product of the weight vector $\omega$ and the input features, plus the bias term $b$: $$z = \omega^T x + b$$
- Pass $z$ through the sigmoid function to obtain the predicted output $\hat{y}$: $$\hat{y} = \sigma(z) = \frac{1}{1 + e^{-z}}$$
- Define the loss function $\mathcal{L}$ as the negative log-likelihood of the predicted output given the true label: $$\mathcal{L} = -\left(y\log(\hat{y}) + (1-y)\log(1-\hat{y})\right)$$ To optimize the weight vector $\omega$, one common method is to compute the derivatives of the loss function with respect to each weight and the bias term, and use these derivatives to update the weights in the opposite direction of the gradient. This is known as gradient descent.
To compute the derivatives, we use the chain rule of derivatives:
$$ \frac{\partial\mathcal{L}}{\partial \omega_i} = \frac{\partial\mathcal{L}}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z} \cdot \frac{\partial z}{\partial \omega_i} $$
$$ \frac{\partial\mathcal{L}}{\partial b} = \frac{\partial\mathcal{L}}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z} \cdot \frac{\partial z}{\partial b} $$
We can then use these derivatives to update the weights as follows:
$$ \omega_i \leftarrow \omega_i - \alpha \frac{\partial \mathcal{L}}{\partial \omega_i} $$
and
$$ b \leftarrow b - \alpha \frac{\partial \mathcal{L}}{\partial b} $$
Where $\alpha$ is the learning rate, which controls the step size of the updates. By iteratively performing these updates on a training set, we can find the optimal weight vector $\omega$ that minimizes the loss function on the training set.
The Derivatives
Let’s begin by computing the derivative of the loss function with respect to the predicted output $\hat{y}$:
$$
\frac{\partial \mathcal{L}}{\partial\hat{y}} =
\frac{\partial}{\partial\hat{y}}
\left(
-\left(y\log(\hat{y}) + (1-y)\log(1-\hat{y})\right)
\right)
$$
Using the chain rule, we get:
$$\frac{\partial \mathcal{L}}{\partial \hat{y}} = -\frac{y}{\hat{y}} + \frac{1-y}{1-\hat{y}}$$ Here, we have used the fact that: $$ \frac{d \space log_a(x)}{dx} = \frac{1}{x\space log(a)} $$
The derivative of the predicted output $\hat{y}$ with respect to $z$:
$$ \frac{\partial\hat{y}}{\partial z} = \frac{\partial}{\partial z} \sigma(z) = \frac{\partial}{\partial z}\frac{1}{1 + e^{-z}} $$
Using the quotient rule, we get: $$ \frac{\partial\hat{y}}{\partial z} = \frac{e^{-z}}{(1 + e^{-z})^2} = \frac{1}{1 + e^{-z}}\cdot \frac{e^{-z}}{1 + e^{-z}} =\hat{y}(1-\hat{y}) $$ Here, we have used the fact that: $$ \sigma(z) = \frac{1}{1 + e^{-z}} $$
The derivative of $z$ with respect to $\omega_i$: $$ \frac{\partial z}{\partial \omega_i} = \frac{\partial}{\partial \omega_i} \omega^T x + b = \frac{\partial}{\partial \omega_i} (\omega_1 x_1 + \dots + w_ix_i+\dots+w_nx_n) + b = x_i $$
Similarly, $$ \frac{\partial z}{\partial b} = \frac{\partial}{\partial b} \omega^T x + b = \frac{\partial}{\partial b} (\omega_1 x_1 + \dots + w_ix_i+\dots+w_nx_n) + b = 1 $$
Therefore
$$ \frac{\partial\mathcal{L}}{\partial \omega_i} = \frac{\partial\mathcal{L}}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z} \cdot \frac{\partial z}{\partial \omega_i} = \left( -\frac{y}{\hat{y}} + \frac{1-y}{1-\hat{y}} \right) \cdot \left( \hat{y}(1-\hat{y}) \right) \cdot \left( x_i \right) = \left( \hat{y} - y \right) x_i $$
and
$$ \frac{\partial\mathcal{L}}{\partial b} = \frac{\partial\mathcal{L}}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z} \cdot \frac{\partial z}{\partial b} = \left( -\frac{y}{\hat{y}} + \frac{1-y}{1-\hat{y}} \right) \cdot \left( \hat{y}(1-\hat{y}) \right) \cdot \left( 1 \right) = \left( \hat{y} - y \right) $$
Extreme Cases
When the predicted value is 1, i.e., $\hat{y}=1$, the derivative of the loss with respect to the predicted output, $\frac{\partial \mathcal{L}}{\partial \hat{y}}$, will be undefined because of the term $\frac{1-y}{1-\hat{y}}$ in the equation.
Similarly, in the case where the predicted value is exactly 0, i.e., $\hat{y}=0$, the derivative of the loss with respect to the predicted output, $\frac{\partial \mathcal{L}}{\partial \hat{y}}$, will also be undefined because of the term $\frac{-y}{\hat{y}}$ in the equation.
In these cases, the backpropagation step cannot proceed as usual, since the derivative of the loss function with respect to the predicted output is a required component. One approach to address this issue is to add a small value $\epsilon$ to $\hat{y}$ in the calculation of the loss function, so that the logarithm term is well-defined. This is sometimes called “label smoothing”.
Another approach is to use a modified loss function that does not have this issue, such as the hinge loss used in support vector machines (SVMs). However, it’s worth noting that logistic regression is a popular and effective method for binary classification, and the issue of undefined derivatives is relatively rare in practice.