The objective of regression is to fit a line through a given data set. Hence, if we are given a set of points;
$$ (x_1, y_1), (x_2, y_2), \dots, (x_i, y_i), \dots ,(x_n, y_n)$$
we want to fit the line $\hat{y} = a_0 + a_1 x$ through the given set of data. The equation $ a_0 + a_1 x$ is known as the hypothesis function.
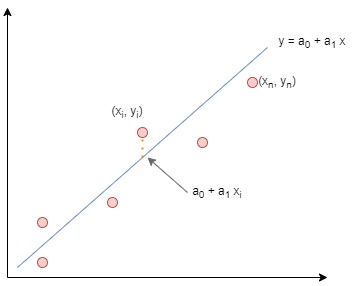
It would be trivial if a line could exactly represent the data provided. Usually, the points will be scattered. Some distance will be present between the line that fits best and the actual data. This distance is the error, also called the residual. It represents the difference between the observed values and the predicted values, that is, for any point $i$,
| $$(Residual)_i$$ | $$ = \hat{y}_i-y_i$$ |
|---|---|
| $$= y_i -(a_0 + a_1 x_i)$$ | |
| $$= y_i - a_0 - a_1 x_i$$ |
The objective is to make the aggregation of residuals as small as possible. This is where the concept of the cost function comes in. The cost function collects all the residuals as a single number and, therefore, measures how well the model is performing. Several cost functions are used; we will examine the three most popular in this post.
Mean Error
This method averages all residuals and is, therefore, the most basic of the cost functions;
$$ME = \frac{\sum_{i=1}^{n} \hat{y}_i-y_i}{n}$$
It is somewhat limited as negative value residuals eliminate positive value residuals. Therefore it is possible to obtain a Mean Error of zero for a terrible approximation.
This method is hence seldom used in practice.
Mean Absolute Error
A logical next step to counter for the deficiencies of the Mean Error calculation is to make all residuals positive by considering the absolute value of the residuals;
$$ME = \frac{\sum_{i=1}^{n} | \hat{y}_i-y_i | }{n}$$
Mean Absolute Error is used where the data being considered contains outliers.
Mean Square Error
Another alternative to counteract the limitations of Mean error is to square the values of the residuals;
$$MSE = \frac{\sum_{i=1}^{n} ( \hat{y}_i-y_i )^{2} }{n}$$
Mean Square Error diminishes the effect of negligible residuals. Still, it also amplifies the other residuals, which can be small in some instances. This method is therefore not recommended when the data contains outliers.
Root Mean Square Error
The Root Mean Square Error is typically used for regression problems when the data does not contain much noise. Similarly to MSE, RMSE will give a higher weight to large residuals.
$$RMSE = \sqrt{ \frac{\sum_{i=1}^{n} ( \hat{y}_i-y_i )^{2} }{n} }$$