Introduction
In the previous posts in this series, we have examined some of the various features of Azure Machine Learning. We have executed some experiments and have seen the results. We will now try to look into a more complete, end to end Machine Learning project in Azure that will utilize leverage the power of other Azure ML features such as:
-
Azure Machine Learning Pipelines. Azure ML pipelines are where we execute discrete steps (or subtasks) as a workflow. It is essential to notice that the pipeline concept is recurrent in many Azure services. In particular, Microsoft suggests using Azure ML pipelines for Model Orchestration, a process that produces a model from data. Another different pipeline type that we might use in Azure is that for data processing, where data produces a new data set. In this case, Microsoft suggests products Azure Data Factory or Azure Data Bricks. Nevertheless, it is possible to use Azure ML pipelines to prepare data if the data transformation is not too complex. Other tasks that we can perform with Azure ML pipelines include:
- Training configuration
- Training and validation
- Repeatable deployments
-
Azure Machine Learning Hyperparameter Tuning. We will use the HyperDrive package to tune the hyperparameters of our machine learning model.
-
Model Deployment into Azure. We will deploy our model into Azure as a web service.
A disclaimer
This collection of posts is not intended to be a complete guide to Azure Machine Learning model building and deployment or a guide towards building machine learning pipelines. It is designed to be a starting point for those interested in using Azure Machine Learning and introduce some of the exciting features available on the platform.
Structure of these posts
This project has been divided into a number of smaller posts so to limit the length and content of each post. It consists of the following entries:
- An introduction to the project, considerations and data uploading to Azure
- Training pipeline creation and execution
- Hyperparameter tuning
- Model Testing
- Model Deployment
AzureML development considerations and project structure
I was inspired by a post in stackoverflow that discussed methods to eliminate sibling import problems to create a consistent project structure for my python projects, thus making all my development projects easier and consistent. I have also completed a template for the project structure creation process, found in this repository. I have named the project as azuremlprojectfor this particular exercise.
At a high level, the project structure is as follows:
azuremlproject This folder contains all the project files.
│ .azureml This folder contains the Azure Machine Learning config files
| data This folder contains the data that will be used in the experiments
| docs This folder contains the documentation for the project
│
└───experiments This folder contains the ML experiments code
│ │ experiment_1 This folder contains the experiment 1
│ │ ...
| |
│ └───experiment_14 This folder contains experiment 14
| | | deploy This folder contains the deployment of the model
| | | optimize This folder contains the hyperparameter optimization
| | | train This folder contains the training of the model
| | | upload This folder uploads of the data required for this experiment
| | | validate This folder contains the validation of the model
| |
| workspace_creation This folder contains the scripts to create workspace
As discussed in the previous posts on this site, I have created several scripts that instantiate the Azure resource group, AzureML Workspace with its Compute resources, and an Azure ML Datastore with the name of the project. One advantage of this approach is that it is easier to delete the resource group and recreate it whenever necessary, thus saving some money. The workspace creation scripts are driven from a parameters file containing the names of the various entities that the user will create, derived from the name of the project. For example, in this project, the project name is set to azmlprj14 and therefore the resource group name is rgazmlprj14, the workspace name is wsazmlprj14 and so on.
Two compute resources are created in the workspace:
- A compute instance with the name instazmlprj14 having type Standard_DS11_v2 (2 cores, 14 GB RAM, 28 GB disk)
- A compute cluster with the name trgazmlprj14 having type Standard_DS3_v2 (4 cores, 14GB RAM, 28GB storage)
The AzureML workspace configuration is then stored in the file .azureml/config.json.
The Project
In this exercise, we will use the UCI Concrete Compressive Strength Dataset, which is both straightforward and easy to use. It is also a small dataset, and therefore we can manipulate and explore the data quickly.
The data set contains the following features:
| Feature | Description | Units | Type |
|---|---|---|---|
| Cement (component 1) | quantitative | kg in a m3 mixture | Input Variable |
| Blast Furnace Slag (component 2) | quantitative | kg in a m3 mixture | Input Variable |
| Fly Ash (component 3) | quantitative | kg in a m3 mixture | Input Variable |
| Water (component 4) | quantitative | kg in a m3 mixture | Input Variable |
| Superplasticizer (component 5) | quantitative | kg in a m3 mixture | Input Variable |
| Coarse Aggregate (component 6) | quantitative | kg in a m3 mixture | Input Variable |
| Fine Aggregate (component 7) | quantitative | kg in a m3 mixture | Input Variable |
| Age | quantitative | Day (1~365) | Input Variable |
| Concrete compressive strength | quantitative | MPa | Output Variable |
To summarize, the data set contains;
- 8 input variables (features)
- 1 output variable (labels)
- all the data is numerical
- feature and label names are pretty long
- 1030 instances in the Dataset
- no missing values in the Dataset
There are many versions of this Dataset, and to load it directly, we have selected a csv version
Data Uploading
The first task of this exercise is to upload the data to Azure ML Datastore and make it available for the experiments through an Azure Machine Learning Dataset. There are many ways to create AzureML Datasets; we will upload a CSV file in this example.
The script required for this task is located under the upload folder.
upload
└───upload_data.py
The steps for uploading the data to the AzureML datastore and registering it as an AzureML Dataframe are the following:
- Get the workspace. If we saved a config file when we created the workspace, we could obtain a reference to the workspace by calling the Workspace.from_config function.
'''
Creates concrete dataset to be used as input for the experiment.
'''
import os
from azureml.core import Workspace, Dataset, Datastore
from azureml.data.datapath import DataPath
from azuremlproject.constants import DATASTORE_NAME
# Name of the dataset.
DATASET_NAME = 'concrete_baseline'
# Load the workspace configuration from the .azureml folder.
config_path = os.path.join(
os.path.dirname(os.path.realpath(__file__)),
'..',
'..',
'.azureml')
w_space = Workspace.from_config(path=config_path)
- Check if the dataset exists. If the dataset does not exists, we can load it, otherwise we can stop
if DATASET_NAME not in Dataset.get_all(w_space).keys():
- Get a reference to the datastore. During the creation of the workspace, we created a datastore with the name bound to the current project. The name of this datastore is contained in a constants file. We use the name to get a reference to the datastore.
data_store = Datastore.get(w_space, DATASTORE_NAME)
- Upload the data to the datastore. We upload the concrete strength dataset to our datastore by calling the datastore.upload function.
# upload all the files in the concrete data folder to the
# default datastore in the workspace concrete_data_baseline folder
data_store.upload(
src_dir=os.path.join(
os.path.dirname(os.path.realpath(__file__)),
'..',
'..',
'data',
'concrete'),
target_path='concrete_data_baseline')
- Register the data as an AzureML Dataframe is carried out in two steps;
- Create the new dataset by calling the Dataset.Tabular.from_delimited_files as the data that we have is tabular. This function requires a DataPath argument that points to the file that we have just uploaded into the datastore.
- Finally, register the dataset by calling the Dataset.register function.
# create a new dataset from the uploaded concrete file
concrete_dataset = Dataset.Tabular.from_delimited_files(
DataPath(data_store, 'concrete_data_baseline/concrete.csv'))
# and register it in the workspace
concrete_dataset.register(
w_space,
'concrete_baseline',
description='Concrete Strength baseline data (w. header)')
print('Dataset uploaded')
else:
print('Dataset already exists')
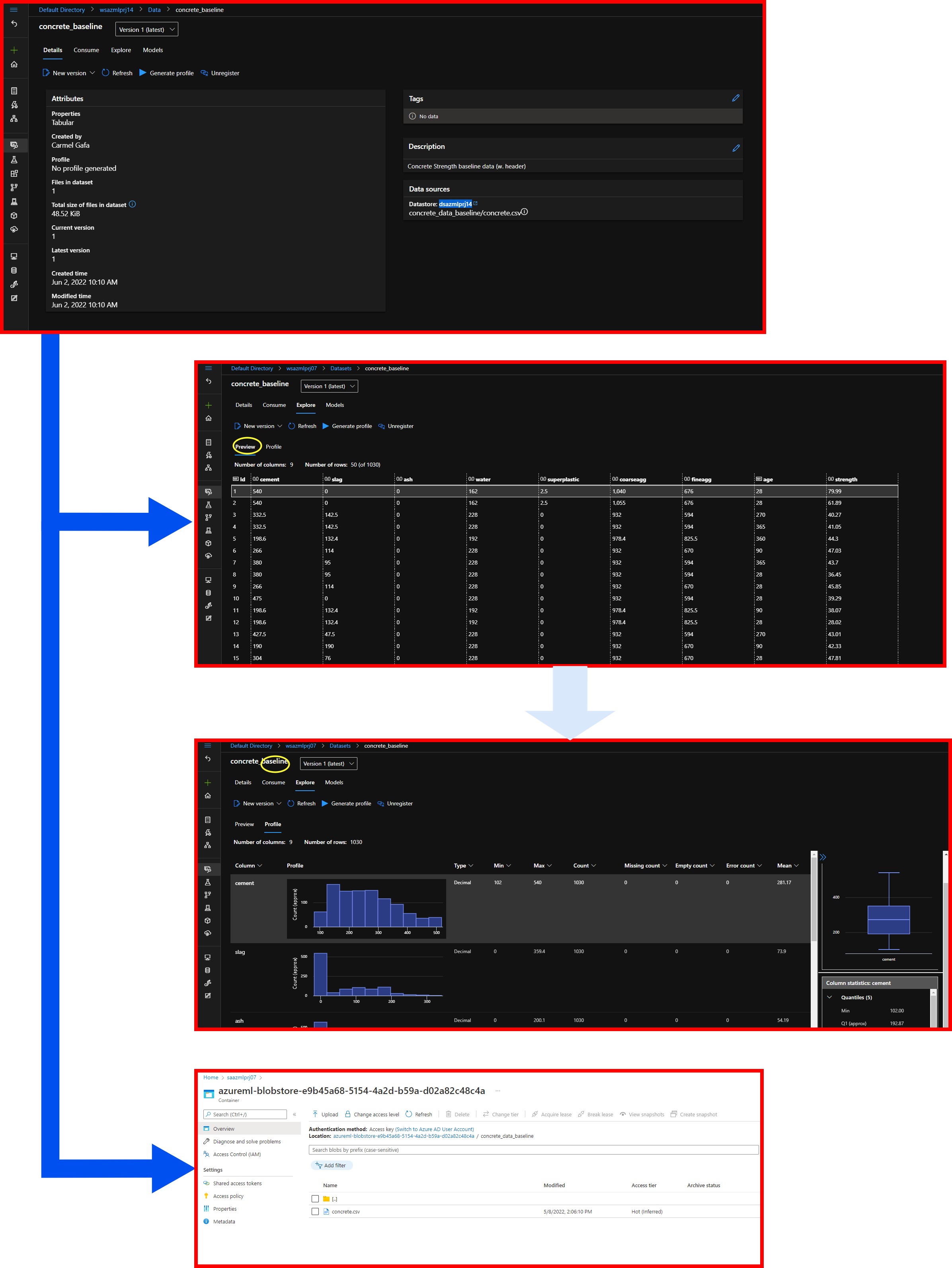
We can verify that the new dataset was correctly created by checking the Datasets tab in AzureML Workspace, where we should find the dataset concrete_baseline. We can also see the Datastore where we uploaded the data, dsazmlprj14, or the associated datastore created with the workspace. We confirm that the data file, concrete.csv, was uploaded to the concrete_data_baseline folder.
We can also look at the dataset by selecting the Explore tab on this page, which directs us to the data dump of the dataset. We can also see that features and labels are all numerical, as they all have a 00 near their name. We can also see that the dataset has 1030 instances.
This screen can also give us a quick overview of the data through the Preview tab. Here we can see the distribution, and information like type, minimum and maximum values and the mean and standard deviation for each feature.
If we click on the datasource link in the Details tab, AzureML will direct us to the blob storage where the data is stored. Here we can see the concrete.csv file.
The figures below show the screens and the links used to navigate through the dataset.
Next Post
In the next post, we will look at creating a pipeline that will enable us to test several different models on the concrete-strength data and select the best performing model.